SCA using Dependency Track (with AWS CDK Deployment Template)
- Midships

- Apr 18, 2024
- 9 min read
Updated: Sep 19, 2025

Introduction
Software Composition Analysis (SCA) is an essential activity in the development of software or infrastructure. It helps reduce the risk of shipping software or infrastructure containing known vulnerabilities within operating systems, 3rd party libraries or binaries. It can also help alert you when your systems, which are already in production, are found to contain new CVEs.
Dependency Track is an open-source application from OWASP that allows you to run an internal system that you can feed with details of your applications and infrastructure, and track your overall risk position regarding these systems and the vulnerabilities that they may contain.
This post should help you to understand how this is valuable for your organisation and also provide you with code to create a deployment of Dependency Track in AWS to allow you to test it out and hopefully reduce your software supply chain risk.
Risk in the Software Supply Chain
Log4J is a ubiquitous logging framework that is present in countless applications, both open-source and bespoke.
Security researchers discovered a remote code exploitation vulnerability in this library in late 2021 (see CVE-2021-44228). A patch was released a month later that removed that vulnerability. But because of the widespread use of this library, it quickly became one of the most widely exploited vulnerabilities out there. This excellent article from Sophos describes the details of the exploit for those interested.
Systems that used a version prior to the patched version were vulnerable to this exploit. Organisations that didn’t have good visibility into their software supply chain didn’t even know what systems they were running in production that were vulnerable to this attack. Some still don’t, as it is still being exploited in 2024.
Software Composition Analysis is the technique that you and your organisation can use to protect yourself with data about your production systems and the software supply chain risk inherent in them.
How SCA using Dependency Track Works
Software Composition Analysis involves creating a Software Bill of Materials (SBOM) at build time that describes the 3rd-party libraries and binaries present in the application or infrastructure components.
An SBOM can easily be created using the Cyclone DX open-source tool in a format supported by Dependency Track.
SBOMs can be created for any type of system that includes operating systems, binaries and or libraries used to host, run or add functionality to those systems. Examples include Java applications packaged with Maven, JavaScript applications packaged with Node Package Manager, Container Images packaged with Docker, Virtual Machine Images packaged with Packer and many more.
The SBOM is uploaded to Dependency Track using its API interface or available open-source tools that provide the integration from your build system to the Dependency Track server. Once the SBOM has been received, it is analysed asynchronously, creating a matrix of data points within Dependency Track detailing the project (name, ID, version, parent etc.) along with the list of libraries and binaries that it holds.
Licence information is also stored within Dependency Track to enable legal, risk and compliance teams to track the software licences that are in use in the systems created by your organisation.
Once analysed in Dependency Track, the application version is continuously assessed against the frequently updated database of known Common Vulnerabilities and Exploits (CVE) listed by organisations like NIST, Sonatype and GitHub. If the application is found to be vulnerable to a newly listed CVE, the risk score of that application is updated accordingly.
This risk score analysis of each application is maintained over the entire portfolio of applications and is displayed over time, from when the application version is first registered in Dependency Track.
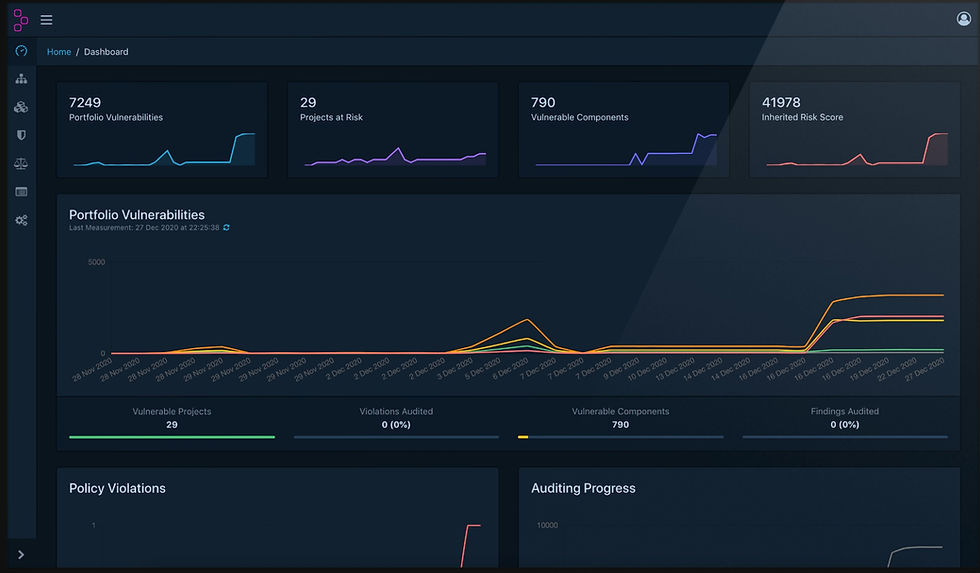
Using this tool your development, security and risk teams have a rich data set that they can use to prioritise the patching of all systems in the fleet. When new critical CVEs are released, all applications tracked with Dependency Track that are vulnerable to this new CVE are easily identified and can be then scheduled for patching.
This provides an extremely powerful view of the software vulnerability posture of the organisation. Personally, the author has seen this pay dividends, allowing an organisation he worked with in the past to patch all systems that were affected by the Log4Shell vulnerability in a few days.
Why is this better than other tools?
While there are many systems available that provide SCA, they have drawbacks:
Docker's Scout is specialised to a particular technology, Docker containers
Dependabot can only be used if you are using GitHub
Artifactory's X-Ray and Sonatype Life Cycle are expensive paid-for products that require significant effort to integrate with, especially in delivery pipelines
Dependency Track is the best of breed in regarding the tracking your software supply chain risk. No other tool provides this level of detail for all types of applications and infrastructure. If you can create an SBOM for it, Dependency Track can track it.
Deploying Dependency Track using the AWS CDK
To help with our mission of reducing fraud and helping to keep our customers secure, we have developed a CDK-based deployment tool for anyone to use, that creates a deployment of Dependency Track in the Amazon Web Services (AWS) cloud platform.
This deployment will allow your organisation to run this tool within your own private cloud, configured and managed by your team.
Alternatively, the code can be used to see how the configuration can be adapted to run it within your own AWS or other cloud infrastructure.
A Note on Cloud Costs
This deployment will cost you roughly $300 USD per month to run. This is due to the large amount of memory required by Dependency Track to run, and the Aurora Postgres database used to store and secure the data that your organisation generates. If you choose at deploy time, to use the embedded database instead of Aurora Postgres, these costs will be reduced though the CDK program does not include external disk storage so this is not recommended as you will lose data if the ECS task is restarted.
Overall, in terms of ROI, this is a small outgoing that can help you have greater visibility of your application security risk over time.
If you don’t find it to be valuable, then a quick execution of the "cdk destroy" command will remove it from your AWS account.
Dependency Track AWS Architecture
Here is the code that you can use to deploy Dependency Track in your org:
The above AWS CDK code deploys Dependency Track by creating the following AWS resources:
A VPC with public and private subnets
An ECS Cluster backed by the minimum size of EC2 instance for running Dependency Track in the public subnet
2 ECS Tasks for the Dependency Track front end and API server components
An optional Aurora Postgres database cluster for storing the data generated
A load balancer to route traffic to the front end for the User Interface and to the API server for build time integration
Does not currently include:
HTTPS configuration for the load balancer
Custom URL management linked to your Route 53 service
This diagram, generated from the CDK output using the cdk-dia tool, shows the architecture:

Deployment Prerequisites
You need the following set up before you start:
The AWS CDK is installed.
A terminal program to run the CDK commands like MacOS Terminal, Git Bash for Windows, or a good old Linux prompt.
An AWS account with access rights to create resources.
The following code steps (using Bash or a similar shell program) will get the Dependency Track application running in your environment in minutes.
Get The Code
Grab the source code from our GitLab repository.
We strongly suggest that you read the code before running the CDK program, so you can be sure you know what resources it will be creating and running inside your AWS account.
Run The Code
Firstly, you will need to make valid AWS credentials available to the shell that you are using. There are a few ways to do this, the simplest is to export temporary credentials as environment variables in your shell environment. AWS provides you these on their login screen.
Remember not to use the above process for production credentials. Better to use the aws cli to log in.
Check the deployment options in the cdk.json file before you run the CDK commands, making sure they are suitable for your use case and environment.
Note that the dependency.track.database.X parameters are only needed if dependency.track.database.embedded is set to false.
"dependency.track.network.vpc.cidr": "10.25.0.0/24", "dependency.track.application.instance.type": "t3.xlarge", "dependency.track.database.embedded": false, "dependency.track.database.instance.type": "t4g.medium", "dependency.track.database.name": "dtrack", "dependency.track.database.username": "dtrack", "dependency.track.database.password": "OverrideThi$"Run the following CDK commands providing approval as needed:
cdk synth --all
cdk deploy --allAccessing Dependency Track
When completed, the CDK program will output the URL that the application can be accessed from. Something like the following:
Outputs: DependencyTrackApplicationStack.DependencyTrackFrontEndAddress = dependencytrack-1234567890.us-east-1.elb.amazonaws.com
Stack ARN: arn:aws:cloudformation:us-east-1:1234567890:stack/DependencyTrackApplicationStack/d67430b2-f880-4639-a946-ad1db96015b8
✨ Total time: 290.25sGrab the URL from the CDK output and put it into a browser.
Remember that HTTPS is not configured on the ALB for this deployment so make sure you enter http explicitly in your browser address bar, for example:
You should be presented with the login page. You can use the default admin credentials to get started:
Username: admin
Password: adminYou will be forced to change the admin the first time you log in.
Dependency Track Vulnerability Sources
Dependency Track follows an eventual consistency model. It receives data from your inputs and from internet vulnerability databases and will parse and update these over time.
When you first deploy the application, it will take some time for it to pull and parse all of the CVE data sources it is configured with out of the box. So give it some time, but in the mean time you can start uploading your data.
Dependency Track Integration
Here, we will show 2 ways you can integrate with the Dependency Track server from the CLI. One using a bash script wrapping Docker’s internal SBOM generation capability, and another is integrated with the Maven build system.
Before starting, go to the admin UI and update the permissions for the API Key already created for API-based integration, e.g.:
Add the following permissions to the Automation Team:
BOM_UPLOAD
PORTFOLIO_MANAGEMENT
PROJECT_CREATION_UPLOAD
VIEW_PORTFOLIO
VIEW_VULNERABILITY

Next, export two environment variables into your linux terminal environment for the next 2 integration approaches to use:
export DEPENDENCY_TRACK_API_KEY=odt_qwertyuiopasdfghjklzxcvbnm export DEPENDENCY_TRACK_BASE_URL=http://dependencytrack-12345679890.us-east-1.elb.amazonaws.com:8081Command Line Integration
To make this easier, we created a bash script that wraps the "docker sbom" command and uses curl to upload the generated SBOM to the Dependency Track server. This is located in the root of the GitLab repository containing the CDK program. Again, its good security sense to read the script before executing it.
Make sure you install the latest version of the Docker SBOM plugin first of all:
The Docker SBOM capability can create an SBOM from any of your container images. This sca.sh script executes that command, then pushes the generated SBOM via API to your Dependency Track server.
This example pulls 2 Ubuntu LTS container images from Docker Hub but you can use any that you have in your local container image cache.
# Generate and upload SBOM for ubuntu:16.04
./sca.sh --image ubuntu --tag 16.04
# Generate and upload SBOM for ubuntu:24.04
./sca.sh --image ubuntu --tag 24.04Then look at the Projects page in the Dependency Track UI for details of these images and the CVEs they contain.
Maven Life Cycle Integration
Dependency Track can be used to provide your teams with fast feedback on the presence of CVEs within the application or infrastructure they are creating at build time, on their local environment or in their build pipelines.
The best time to do this kind of integration with Dependency Track is before committing to the source code repository, i.e. from a local development environment. Additionally, this integration should be a mandatory part of your build pipelines that run before code is merged to the main branch of your code repository.
To facilitate this kind of development and build time validation of your application, a number of open-source tools exist. This example show how to use the Maven build system along with a Dependency Track plugin to get fast feedback on vulnerabilities in your application or infrastructure.
Dependency Track Maven Plugin
The author has previously created an open-source tool for integrating the Maven build system with the Dependency Track server.
Full details can be found on the GitHub page for that project:
Check the profiles in the pom.xml file for an example on how to use this.
Other Dependency Track Integrations
Dependency Track has a rich integration ecosystem, both in terms of data sources for vulnerabilities and build and analysis tools for integration in your environment.
Check them all out here: Ecosystem Overview
Support to Integrate
If you need help deploying Dependency Track, or implementing an integration to it from your pipelines, then get in touch with Midships. Our team of DevSecOps experts have considerable experience with this tool and can help you to get the best from it.
We can help you to configure the Dependency Track application, tweak the cloud deployment or deploy on-premise, integrate your delivery pipelines to Dependency Track or help your security teams with understanding its use and setting internal policy regarding SCA for your teams to adhere to.
Are you interested?
If you would like to learn more, please contact sales@midships.io



Comments